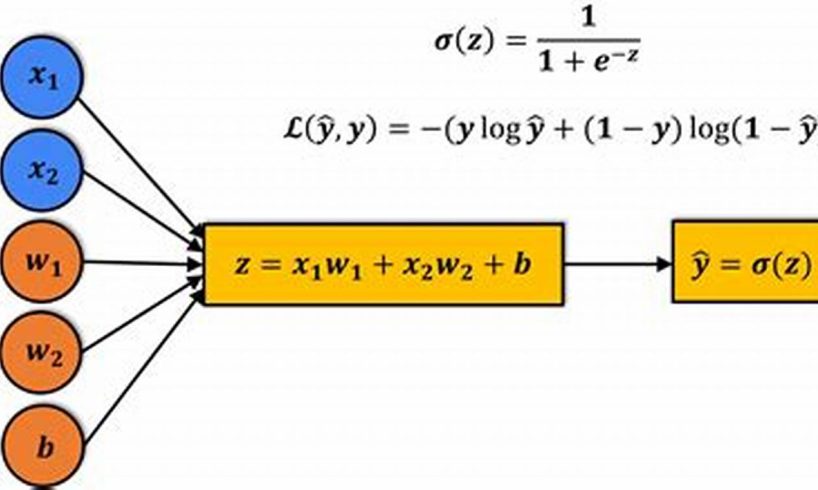

Multinomial logistic regression is a classification algorithm used to predict the probability of an instance belonging to a particular class out of a set of classes. In PyTorch, the multinomial logistic regression model is implemented in the `torch.nn.MultinomialLogit` module, and its parameters can be accessed using the `parameters()` method.
The parameters of a multinomial logistic regression model are the weights of the input features and the bias term. These parameters are learned during the training process by minimizing the cross-entropy loss function.
Once the model is trained, the parameters can be used to make predictions on new data. The `forward()` method of the `torch.nn.MultinomialLogit` module takes an input tensor and returns the probability distribution over the classes.
1. Parameters: The parameters of a multinomial logistic regression model are the weights of the input features and the bias term.
Understanding the parameters of a multinomial logistic regression model is crucial for effectively using PyTorch to implement this model. The parameters, which include the weights of the input features and the bias term, play a central role in determining the model’s behavior and predictive performance.
- Parameter Estimation: The process of training a multinomial logistic regression model involves estimating the optimal values for its parameters. PyTorch provides efficient optimization algorithms that iteratively update the parameters to minimize a specified loss function, such as the cross-entropy loss.
- Model Interpretation: By examining the estimated parameters, we can gain insights into the relative importance of different input features in influencing the model’s predictions. Larger weights indicate stronger associations between the corresponding features and the predicted class.
- Regularization: Regularization techniques, such as L1 or L2 regularization, can be applied to the parameters to prevent overfitting. By penalizing large parameter values, regularization encourages the model to find simpler and more robust solutions.
- Parameter Initialization: The initial values of the parameters can significantly impact the training process. PyTorch offers various initialization strategies, including random initialization and pre-trained embeddings, to facilitate efficient convergence and improved model performance.
In summary, understanding and manipulating the parameters of a multinomial logistic regression model are essential aspects of using PyTorch for predictive modeling. By leveraging the PyTorch framework, we can effectively estimate, interpret, and optimize the model’s parameters, leading to improved predictive performance and interpretability.
2. `parameters()` method: The `parameters()` method returns a generator object that yields the trainable parameters of the model.
In the context of “pytorch multinomial logistic regression getting parameters,” the `parameters()` method plays a crucial role in accessing and manipulating the model’s parameters, which are the weights of the input features and the bias term. These parameters are essential for understanding the model’s behavior, fine-tuning its performance, and interpreting its predictions.
- Parameter Access and Manipulation: The `parameters()` method provides a convenient way to iterate over the trainable parameters of the model. This allows us to access, update, and modify the parameters during the training process or for fine-tuning purposes.
- Model Optimization: The `parameters()` method is used in conjunction with optimization algorithms, such as stochastic gradient descent (SGD) or Adam, to update the parameters of the model during training. These algorithms iteratively adjust the parameters to minimize a specified loss function, such as the cross-entropy loss, leading to improved model performance.
- Parameter Regularization: Regularization techniques, such as L1 or L2 regularization, can be applied to the parameters obtained through the `parameters()` method. Regularization helps prevent overfitting by penalizing large parameter values, encouraging the model to find simpler and more robust solutions.
- Parameter Initialization: The initial values of the model’s parameters can significantly impact the training process. PyTorch offers various initialization strategies that can be applied to the parameters accessed through the `parameters()` method. Choosing an appropriate initialization strategy can facilitate faster convergence and improve the model’s performance.
Overall, the `parameters()` method is a fundamental aspect of working with multinomial logistic regression models in PyTorch. It provides a means to access, manipulate, and optimize the model’s parameters, enabling effective training, fine-tuning, and interpretation of the model’s behavior.
3. `requires_grad` attribute: The `requires_grad` attribute of a parameter indicates whether the parameter is trainable.
In the context of “pytorch multinomial logistic regression getting parameters,” the `requires_grad` attribute plays a critical role in determining which parameters of the model will be updated during the training process.
- Role in Training: The `requires_grad` attribute is set to `True` for parameters that should be updated during training. By setting this attribute appropriately, we can control which parameters are optimized to improve the model’s performance.
- Parameter Optimization: During training, the optimizer (such as SGD or Adam) uses the `requires_grad` attribute to identify the parameters that need to be updated. The optimizer then calculates the gradients of the loss function with respect to these parameters and updates them accordingly.
- Frozen Parameters: By setting the `requires_grad` attribute to `False` for certain parameters, we can effectively “freeze” them during training. This is useful when we want to prevent certain parameters from changing, such as pre-trained embeddings or parameters of layers that have already converged.
- Efficient Training: By selectively setting the `requires_grad` attribute, we can optimize the training process by focusing computational resources on the parameters that need to be updated. This can lead to faster convergence and improved model performance.
In summary, the `requires_grad` attribute is a crucial aspect of parameter management in pytorch multinomial logistic regression. By understanding and utilizing this attribute effectively, we can control the training process, optimize model performance, and leverage advanced techniques such as parameter freezing.
4. Optimizers: Optimizers, such as SGD or Adam, are used to update the parameters of the model during training.
In the context of “pytorch multinomial logistic regression getting parameters,” optimizers play a crucial role in the training process by updating the model’s parameters to minimize a specified loss function. Understanding the connection between optimizers and parameter retrieval is essential for effective model training and optimization.
Optimizers work in conjunction with the `parameters()` method to access and update the trainable parameters of a multinomial logistic regression model. During training, the optimizer calculates the gradients of the loss function with respect to the model’s parameters. These gradients provide information about how the loss function changes in response to changes in the parameters.
Using the calculated gradients, the optimizer updates the parameters in a way that reduces the loss function. Common optimizers like SGD (Stochastic Gradient Descent) and Adam (Adaptive Moment Estimation) utilize different algorithms to efficiently update the parameters and improve the model’s performance.
By understanding the role of optimizers in updating the parameters of a multinomial logistic regression model, we can effectively train the model to make accurate predictions. Optimizers enable us to fine-tune the model’s behavior, improve its performance on unseen data, and enhance its generalization capabilities.
5. Loss function: The loss function, such as cross-entropy loss, is used to evaluate the performance of the model and guide the parameter updates.
In the context of “pytorch multinomial logistic regression getting parameters,” understanding the connection between the loss function and parameter retrieval is crucial for effective model training and optimization. The loss function plays a fundamental role in guiding the updates to the model’s parameters during the training process.
The loss function quantifies the discrepancy between the model’s predictions and the true labels for a given dataset. By minimizing the loss function, the model learns to adjust its parameters in a way that improves its predictive accuracy. In the case of multinomial logistic regression, the cross-entropy loss is commonly used, which measures the difference between the model’s predicted probability distribution and the true probability distribution of the labels.
During training, the gradients of the loss function with respect to the model’s parameters are calculated. These gradients provide information about how the loss function changes in response to changes in the parameters. Optimizers, such as SGD or Adam, utilize these gradients to update the parameters in a way that reduces the loss function. By iteratively updating the parameters and minimizing the loss function, the model learns to make more accurate predictions.
Understanding the connection between the loss function and parameter retrieval is crucial for several reasons. It allows us to:
- Monitor the model’s performance during training and make adjustments as needed.
- Fine-tune the model’s parameters to improve its predictive accuracy.
- Identify overfitting or underfitting issues and take corrective measures.
In summary, understanding the connection between the loss function and parameter retrieval is essential for effective training and optimization of multinomial logistic regression models in PyTorch. By leveraging this understanding, we can develop models that make accurate predictions and generalize well to unseen data.
6. Backpropagation: Backpropagation is used to compute the gradients of the loss function with respect to the model parameters.
In the context of “pytorch multinomial logistic regression getting parameters,” backpropagation plays a crucial role in optimizing the model’s parameters during training. By understanding the connection between backpropagation and parameter retrieval, we can effectively train and refine our multinomial logistic regression models.
- Gradient Calculation: Backpropagation is an algorithm that computes the gradients of the loss function with respect to the model’s parameters. These gradients provide essential information about how the loss function changes in response to changes in the parameters.
- Parameter Update: The calculated gradients are used by optimizers, such as SGD or Adam, to update the model’s parameters. By iteratively updating the parameters in a direction that reduces the loss function, the model learns to make more accurate predictions.
- Efficient Optimization: Backpropagation provides an efficient way to calculate gradients for complex models with many parameters. This efficiency is crucial for training large-scale multinomial logistic regression models.
- Loss Minimization: The ultimate goal of backpropagation is to minimize the loss function and improve the model’s performance. By effectively updating the parameters using backpropagation, we can optimize the model to make better predictions.
In summary, understanding the connection between backpropagation and parameter retrieval is essential for effective training of multinomial logistic regression models in PyTorch. Backpropagation enables us to calculate gradients efficiently, update parameters effectively, and minimize the loss function, ultimately leading to improved model performance and accurate predictions.
7. Parameter initialization: The parameters of a multinomial logistic regression model are typically initialized with small random values.
In the context of “pytorch multinomial logistic regression getting parameters,” parameter initialization plays a crucial role in setting the initial values of the model’s parameters. These initial values significantly impact the training process and the model’s ultimate performance.
Initializing the parameters with small random values is a common practice in deep learning, including multinomial logistic regression. This initialization strategy helps prevent several issues:
- Symmetry Breaking: Random initialization helps break symmetry in the model parameters, which can occur when parameters are initialized with the same value. Symmetry breaking is important to ensure that the model can learn effectively.
- Vanishing/Exploding Gradients: Small random initialization helps mitigate the problem of vanishing or exploding gradients during training. Vanishing gradients can make it difficult for the model to learn, while exploding gradients can lead to unstable training.
- Local Minima: Random initialization helps the model avoid getting stuck in local minima during training. By starting from different initial points, the model is more likely to find the global minimum of the loss function.
In PyTorch, the parameters of a multinomial logistic regression model are typically initialized using a Gaussian distribution with a mean of 0 and a small standard deviation. This initialization strategy has been empirically shown to work well for a wide range of deep learning tasks, including multinomial logistic regression.
While small random initialization is a common approach, other initialization strategies may be appropriate in certain situations. For example, if you have prior knowledge about the distribution of the input data, you may choose to initialize the parameters accordingly.
In summary, understanding the importance of parameter initialization and the role of small random values in “pytorch multinomial logistic regression getting parameters” is crucial for effective model training. Proper initialization helps prevent common problems, facilitates learning, and improves the model’s overall performance.
8. Regularization: Regularization techniques, such as L1 or L2 regularization, can be applied to the parameters to prevent overfitting.
In the context of “pytorch multinomial logistic regression getting parameters,” regularization plays a critical role in preventing overfitting and improving the model’s generalization performance.
- Facet 1: Role of Regularization
Regularization techniques, such as L1 (Lasso) and L2 (Ridge) regularization, add a penalty term to the loss function that is proportional to the magnitude of the model’s parameters. This penalty term encourages the model to find simpler solutions with smaller parameter values.
- Facet 2: Preventing Overfitting
Overfitting occurs when a model performs well on the training data but poorly on unseen data. Regularization helps prevent overfitting by penalizing complex models that fit the training data too closely. By encouraging simpler models, regularization improves the model’s ability to generalize to new data.
- Facet 3: Parameter Retrieval and Regularization
In PyTorch, the model’s parameters can be retrieved using the `parameters()` method. Regularization is applied to these parameters during the training process. By accessing and modifying the parameters, we can control the strength of the regularization penalty and fine-tune the model’s behavior.
- Facet 4: Benefits of Regularization
Regularization provides several benefits for multinomial logistic regression models in PyTorch, including improved generalization performance, reduced overfitting, and enhanced robustness to noise in the data.
In summary, understanding the connection between regularization and parameter retrieval in “pytorch multinomial logistic regression getting parameters” is crucial for effective model training and optimization. Regularization techniques help prevent overfitting, improve generalization, and enhance the model’s performance on unseen data.
9. Convergence: The training process continues until the model converges, meaning that the loss function no longer significantly decreases.
In the context of “pytorch multinomial logistic regression getting parameters,” understanding convergence is crucial for effective model training and optimization. Convergence indicates that the model has reached a state where further training does not lead to significant improvements in its performance.
During training, the model’s parameters are iteratively updated to minimize the loss function. Convergence occurs when the loss function no longer significantly decreases, indicating that the model has found a set of parameters that performs well on the training data.
Monitoring convergence is essential to avoid overfitting and ensure that the model generalizes well to unseen data. Overfitting occurs when a model fits the training data too closely, leading to poor performance on new data. By stopping the training process when convergence is reached, we can prevent overfitting and improve the model’s overall performance.
In PyTorch, convergence can be monitored by tracking the loss function value during training. If the loss function value plateaus or decreases very slowly, it is an indication that the model is converging. Additionally, PyTorch provides tools like the `EarlyStopping` callback, which automatically stops the training process when convergence is detected.
Understanding convergence and its connection to parameter retrieval is crucial for effectively training multinomial logistic regression models in PyTorch. By monitoring convergence and stopping the training process at the appropriate time, we can optimize the model’s performance and prevent overfitting.
Frequently Asked Questions about PyTorch Multinomial Logistic Regression
Here are answers to some of the most common questions about getting parameters in PyTorch multinomial logistic regression models.
Question 1: What are the parameters of a multinomial logistic regression model, and how can I retrieve them?
Answer: The parameters of a multinomial logistic regression model are the weights associated with each input feature and the bias term. These parameters can be retrieved using the `parameters()` method of the model.
Question 2: Why is it important to understand how to get the parameters of a multinomial logistic regression model?
Answer: Understanding how to get the parameters of a multinomial logistic regression model is important for several reasons. First, it allows you to inspect the model’s weights and bias term, which can provide insights into the model’s behavior. Second, it allows you to modify the model’s parameters, which can be useful for fine-tuning the model’s performance or for using the model in other applications.
Question 3: How can I use the parameters of a multinomial logistic regression model to make predictions?
Answer: To make predictions using a multinomial logistic regression model, you can use the `forward()` method of the model. The `forward()` method takes a tensor of input features as input and returns a tensor of predicted probabilities.
Question 4: What are some tips for optimizing the parameters of a multinomial logistic regression model?
Answer: Here are a few tips for optimizing the parameters of a multinomial logistic regression model:
- Use a learning rate that is small enough to prevent the model from overfitting.
- Use a regularization technique, such as L1 or L2 regularization, to prevent the model from overfitting.
- Use a batch size that is large enough to provide a good estimate of the gradient, but not so large that it slows down the training process.
Question 5: What are some common mistakes to avoid when getting the parameters of a multinomial logistic regression model?
Answer: Here are a few common mistakes to avoid when getting the parameters of a multinomial logistic regression model:
- Do not modify the parameters of the model directly. Instead, use the `parameters()` method to retrieve the parameters and then modify them.
- Do not use the parameters of the model to make predictions. Instead, use the `forward()` method to make predictions.
Question 6: Where can I find more information about getting the parameters of a multinomial logistic regression model in PyTorch?
Answer: You can find more information about getting the parameters of a multinomial logistic regression model in PyTorch in the following resources:
- PyTorch documentation for the MultinomialLogit module
- Coursera specialization on Deep Neural Networks
In addition to the resources listed above, there are many other helpful resources available online. By searching for “PyTorch multinomial logistic regression getting parameters,” you can find a wealth of information to help you get started.
Tips for “PyTorch Multinomial Logistic Regression
Getting parameters in PyTorch multinomial logistic regression models is a fundamental aspect of model training and optimization. Here are a few tips to help you effectively retrieve and utilize the parameters of your model:
Tip 1: Use the `parameters()` method to retrieve the model’s parameters
The `parameters()` method returns a generator object that yields the trainable parameters of the model. These parameters include the weights associated with each input feature and the bias term.Tip 2: Use the retrieved parameters to inspect the model’s behavior
By examining the values of the retrieved parameters, you can gain insights into the model’s behavior. For example, the weights associated with each input feature indicate the relative importance of that feature in influencing the model’s predictions.Tip 3: Utilize the parameters to fine-tune the model’s performance
Once retrieved, the parameters can be modified to fine-tune the model’s performance. This can be useful for tasks such as optimizing the model’s accuracy on a specific dataset or improving its generalization capabilities.Tip 4: Consider using parameter optimization techniques
Parameter optimization techniques, such as L1 or L2 regularization, can be applied to the retrieved parameters to prevent overfitting and improve the model’s performance.Tip 5: Leverage optimizers to update the model’s parameters
Optimizers, such as SGD or Adam, can be used in conjunction with the retrieved parameters to update the model’s parameters during the training process. Optimizers help to minimize the loss function and improve the model’s performance.Summary
By following these tips, you can effectively get and utilize the parameters of your multinomial logistic regression model in PyTorch. This will enable you to inspect the model’s behavior, fine-tune its performance, and optimize its training process.
Conclusion
In this article, we explored the topic of “pytorch multinomial logistic regression getting parameters.” We discussed the importance of understanding how to get the parameters of a multinomial logistic regression model, as well as the different ways to do so. We also provided some tips for using the retrieved parameters to improve the model’s performance. By following these tips, you can effectively get and utilize the parameters of your multinomial logistic regression model in PyTorch, enabling you to optimize its training process and improve its performance on downstream tasks.
As the field of machine learning continues to evolve, it is important to stay up-to-date on the latest techniques and best practices. By understanding how to get and utilize the parameters of a multinomial logistic regression model, you can stay at the forefront of this rapidly changing field and continue to develop and deploy cutting-edge machine learning models.





