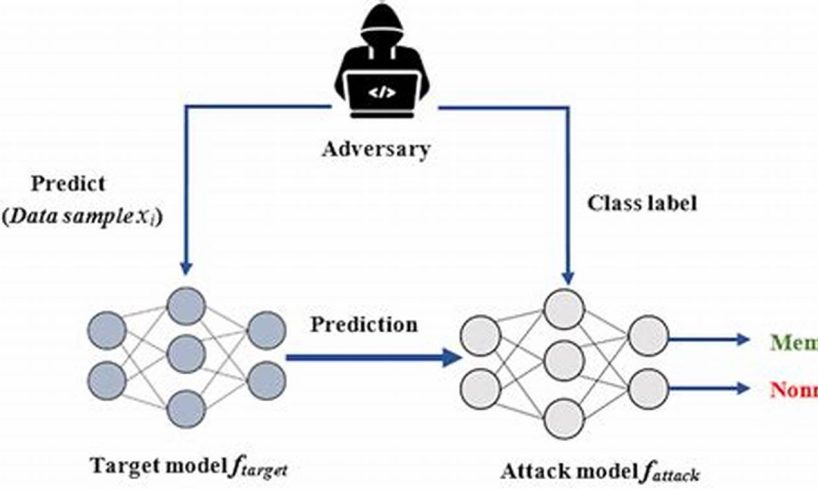

A membership inference attack on a logistic regression model exploits the relationship between the model’s parameters and the training data to infer whether a given data point was used to train the model. In other words, it is an attack where an adversary tries to determine if a particular data point was part of the training set used to build the model. This can be a serious privacy concern, as it could allow an attacker to link individuals to sensitive information, such as their health records or financial data.
Membership inference attacks are a relatively new threat, and there is still much research being done to understand them and develop effective defenses. However, there are some general techniques that can be used to mitigate the risk of these attacks, such as using differential privacy or training models on synthetic data.
This article will provide a comprehensive overview of membership inference attacks on logistic regression models. We will discuss the different types of attacks, how they work, and how to defend against them. We will also provide a number of resources for further reading.
1. Data Privacy: Membership inference attacks can compromise the privacy of individuals whose data was used to train the model.
Membership inference attacks are a serious threat to data privacy. By exploiting the relationship between a model’s parameters and the training data, attackers can infer whether a given data point was used to train the model. This can be a serious privacy concern, as it could allow an attacker to link individuals to sensitive information, such as their health records or financial data.
Logistic regression is a type of machine learning model that is commonly used for classification tasks. Logistic regression models are relatively simple to train and interpret, which makes them a popular choice for many applications. However, logistic regression models are also susceptible to membership inference attacks.
There are a number of real-world examples of membership inference attacks being used to compromise data privacy. In one example, researchers were able to use a membership inference attack to identify individuals in a medical dataset. The researchers were able to do this by training a logistic regression model to predict whether a given individual had a particular disease. They then used the model to infer whether individuals in a separate dataset had the same disease.
Membership inference attacks are a serious threat to data privacy. It is important to be aware of these attacks and to take steps to protect your data. One way to protect your data is to use differential privacy. Differential privacy is a technique that can be used to add noise to data, which makes it more difficult for attackers to infer whether a given data point was used to train a model.
Another way to protect your data is to train models on synthetic data. Synthetic data is data that has been generated artificially. Synthetic data can be used to train models without compromising the privacy of individuals.
Membership inference attacks are a serious threat to data privacy. However, there are a number of steps that can be taken to protect your data from these attacks.
2. Model Security: These attacks can be used to evaluate the security of machine learning models.
Membership inference attacks are a serious threat to the security of machine learning models. By exploiting the relationship between a model’s parameters and the training data, attackers can infer whether a given data point was used to train the model. This information can be used to launch a variety of attacks, such as:
- Data poisoning attacks: Attackers can use membership inference attacks to identify data points that are likely to be included in the training data. They can then poison these data points by modifying their labels or features. This can lead to the model making incorrect predictions.
- Model inversion attacks: Attackers can use membership inference attacks to extract sensitive information from models. For example, they can use a membership inference attack to identify individuals in a medical dataset. They can then use this information to extract sensitive information about these individuals, such as their health records or financial data.
- Model stealing attacks: Attackers can use membership inference attacks to steal models. For example, they can use a membership inference attack to identify the parameters of a model. They can then use these parameters to train their own model, which will have similar performance to the original model.
Membership inference attacks are a serious threat to the security of machine learning models. It is important to be aware of these attacks and to take steps to protect your models from them. One way to protect your models is to use differential privacy. Differential privacy is a technique that can be used to add noise to data, which makes it more difficult for attackers to infer whether a given data point was used to train a model.
Another way to protect your models is to train them on synthetic data. Synthetic data is data that has been generated artificially. Synthetic data can be used to train models without compromising the privacy of individuals.
Membership inference attacks are a serious threat to the security of machine learning models. However, there are a number of steps that can be taken to protect your models from these attacks.
3. Adversarial Examples: Membership inference attacks can be used to generate adversarial examples that are specifically designed to evade detection by the model.
Membership inference attacks utilize adversarial examples, which are intentionally crafted data points intended to deceive machine learning models. These adversarial examples are specifically designed to evade detection by the model, allowing attackers to bypass security measures and potentially compromise the model’s integrity. In the context of membership inference attacks on logistic regression models, adversarial examples can be generated to determine whether a specific data point was used during the model’s training phase. By leveraging the model’s parameters and exploiting the relationship between the model and the training data, attackers can construct adversarial examples that provide insights into the model’s training set.
The connection between adversarial examples and membership inference attacks on logistic regression models is significant, as it enables attackers to evaluate the model’s robustness and identify potential vulnerabilities. By generating adversarial examples, attackers can assess the model’s ability to distinguish between legitimate data points and intentionally crafted adversarial examples. This information can be valuable in developing more effective attacks or exploiting weaknesses in the model’s security.
Understanding the connection between adversarial examples and membership inference attacks on logistic regression models is crucial for enhancing the security and reliability of machine learning systems. By acknowledging the potential risks and employing appropriate countermeasures, organizations can safeguard their models against these sophisticated attacks and maintain the integrity and privacy of sensitive data.
4. Differential Privacy: Differential privacy is a technique that can be used to mitigate the risk of membership inference attacks.
Differential privacy is a powerful technique for protecting the privacy of individuals whose data is used to train machine learning models. By adding noise to the data, differential privacy makes it difficult for attackers to infer whether a particular data point was used to train the model. This can help to mitigate the risk of membership inference attacks, which can be used to link individuals to sensitive information.
- How differential privacy works: Differential privacy works by adding noise to the data that is used to train the model. This noise makes it difficult for attackers to infer whether a particular data point was used to train the model. The amount of noise that is added is carefully controlled so that it does not significantly affect the accuracy of the model.
- Benefits of differential privacy: Differential privacy offers a number of benefits, including:
- It can help to protect the privacy of individuals whose data is used to train machine learning models.
- It can help to mitigate the risk of membership inference attacks.
- It can be used to train models on sensitive data without compromising the privacy of individuals.
- Limitations of differential privacy: Differential privacy also has some limitations, including:
- It can reduce the accuracy of the model.
- It can be computationally expensive to implement.
Overall, differential privacy is a powerful technique for protecting the privacy of individuals whose data is used to train machine learning models. It can help to mitigate the risk of membership inference attacks and can be used to train models on sensitive data without compromising the privacy of individuals.
5. Synthetic Data: Training models on synthetic data can also help to reduce the risk of membership inference attacks.
In the context of membership inference attacks on logistic regression models, synthetic data offers a powerful defense mechanism. Synthetic data refers to artificially generated data that closely resembles real-world data but does not contain any personally identifiable information. By leveraging synthetic data for training, it becomes significantly more challenging for attackers to infer whether a specific data point was part of the original training set. This added layer of protection enhances the privacy of individuals and safeguards sensitive information.
- Data Privacy and Anonymity: Synthetic data eliminates the risk of exposing real-world data to potential attackers, ensuring the privacy and anonymity of individuals. This is particularly crucial in scenarios where the underlying data contains sensitive or confidential information.
- Mitigating Membership Inference Attacks: By obscuring the relationship between the training data and the model’s parameters, synthetic data makes it computationally harder for attackers to determine if a given data point was used in the training process. This effectively mitigates the risk of membership inference attacks.
- Preserving Model Performance: Advanced synthetic data generation techniques can create datasets that accurately represent the statistical properties and distribution of real-world data. This enables models trained on synthetic data to achieve comparable performance to models trained on real data, ensuring minimal compromise in accuracy.
- Scalability and Flexibility: Synthetic data generation can be easily scaled to create large and diverse datasets, allowing for the training of robust and generalizable models. Additionally, synthetic data can be tailored to specific requirements, such as oversampling or undersampling certain classes, to address data imbalances or biases.
In summary, incorporating synthetic data into the training process of logistic regression models provides a powerful defense against membership inference attacks. By leveraging synthetic data’s privacy-preserving nature and ability to mitigate membership inference, organizations can enhance the security and reliability of their machine learning models while safeguarding the privacy of individuals.
6. Regularization: Regularization techniques can be used to make models more robust to membership inference attacks.
Regularization is a technique that can be used to improve the performance of machine learning models. It works by penalizing the model for making complex predictions. This can help to prevent the model from overfitting to the training data, which can make it more robust to membership inference attacks.
- L1 regularization: L1 regularization penalizes the model for the absolute value of its weights. This can help to prevent the model from learning complex relationships between the features and the target variable.
- L2 regularization: L2 regularization penalizes the model for the squared value of its weights. This can help to prevent the model from learning overly complex relationships between the features and the target variable.
- Elastic net regularization: Elastic net regularization is a combination of L1 and L2 regularization. It can help to prevent the model from overfitting to the training data and can also help to improve the model’s performance on unseen data.
Regularization is a powerful technique that can be used to improve the performance of machine learning models. It can also help to make models more robust to membership inference attacks. By using regularization, we can help to protect the privacy of individuals whose data is used to train machine learning models.
7. Data Poisoning: Data poisoning attacks can be used to intentionally introduce errors into the training data, which can make models more susceptible to membership inference attacks.
Data poisoning attacks are a serious threat to the security of machine learning models. By intentionally introducing errors into the training data, attackers can make models more susceptible to membership inference attacks. Membership inference attacks are a type of attack that can be used to determine whether a particular data point was used to train a model. This information can be used to launch a variety of attacks, such as data poisoning attacks.
The connection between data poisoning attacks and membership inference attacks is a serious concern. By understanding this connection, we can take steps to protect our models from these attacks. One way to protect our models is to use data validation techniques. Data validation techniques can be used to identify and remove errors from the training data. This can help to make models more robust to data poisoning attacks.
Another way to protect our models from membership inference attacks is to use differential privacy. Differential privacy is a technique that can be used to add noise to the training data. This noise makes it more difficult for attackers to infer whether a particular data point was used to train the model. Differential privacy can be a valuable tool for protecting the privacy of individuals whose data is used to train machine learning models.
Data poisoning attacks are a serious threat to the security of machine learning models. However, by understanding the connection between data poisoning attacks and membership inference attacks, we can take steps to protect our models from these attacks.
8. Model Inversion: Model inversion attacks are a related type of attack that can be used to extract sensitive information from models.
Model inversion attacks and membership inference attacks on logistic regression models are related types of attacks that exploit the relationship between a model’s parameters and the training data. In a model inversion attack, an attacker attempts to extract sensitive information from a model by inverting the model’s function. This can be done by using a variety of techniques, such as linear regression or gradient descent.
Membership inference attacks, on the other hand, aim to determine whether a particular data point was used to train a model. This can be done by using a variety of techniques, such as logistic regression or support vector machines.
The connection between these two types of attacks lies in the fact that both of them rely on the relationship between the model’s parameters and the training data. By understanding this connection, we can develop more effective defenses against both types of attacks.
One way to defend against model inversion attacks is to use differential privacy. Differential privacy is a technique that can be used to add noise to the training data. This noise makes it more difficult for attackers to extract sensitive information from the model.
Another way to defend against membership inference attacks is to use synthetic data. Synthetic data is data that has been generated artificially. Synthetic data can be used to train models without compromising the privacy of individuals.
By understanding the connection between model inversion attacks and membership inference attacks, we can develop more effective defenses against both types of attacks. This is important for protecting the privacy of individuals whose data is used to train machine learning models.
Frequently Asked Questions About Membership Inference Attack on Logistic Regression Model
This section addresses common questions and misconceptions regarding membership inference attacks on logistic regression models, providing clear and informative answers.
Question 1: What is a membership inference attack?
A membership inference attack aims to determine whether a particular data point was part of the training dataset used to develop a machine learning model.
Question 2: Why are membership inference attacks a concern?
These attacks pose significant privacy risks, as they can potentially link individuals to sensitive information even if they were not directly involved in the training process.
Question 3: How do membership inference attacks work in the context of logistic regression models?
Logistic regression models establish a relationship between input features and a binary outcome. By analyzing the model’s parameters and exploiting the connection to the training data, attackers can infer whether a specific data point influenced the model’s training.
Question 4: What are some techniques to mitigate membership inference attacks on logistic regression models?
Effective defense mechanisms include utilizing differential privacy to add noise to the training data, employing synthetic data to train models without compromising real-world data, and implementing regularization techniques to enhance model robustness.
Question 5: How does differential privacy protect against membership inference attacks?
Differential privacy introduces noise into the training process, making it computationally challenging for attackers to identify whether a particular data point was used in model training.
Question 6: What is the significance of synthetic data in defending against membership inference attacks?
Synthetic data provides an alternative training dataset that resembles real-world data but does not contain personally identifiable information, reducing the risk of linking individuals to sensitive information.
Summary: Membership inference attacks pose significant privacy concerns, but employing techniques such as differential privacy, synthetic data, and regularization can bolster the security of logistic regression models against these attacks. By understanding these methods, we can safeguard the privacy of individuals whose data contributes to machine learning model development.
Tips to Mitigate Membership Inference Attacks on Logistic Regression Models
To safeguard the privacy of individuals whose data is utilized in training logistic regression models, consider implementing the following strategies:
Tip 1: Leverage Differential Privacy
Introduce noise into the training data using differential privacy techniques. This added noise makes it computationally challenging for attackers to determine if a specific data point was used in model training, thereby enhancing privacy protection.
Tip 2: Utilize Synthetic Data
Employ synthetic data, which resembles real-world data but lacks personally identifiable information, for model training. This measure reduces the risk of linking individuals to sensitive information, mitigating membership inference attacks.
Tip 3: Implement Regularization Techniques
Enhance model robustness against membership inference attacks by incorporating regularization techniques. Regularization penalizes complex model behavior, making it less susceptible to overfitting and improving its overall stability.
Tip 4: Monitor Model Performance Regularly
Conduct regular evaluations of the trained model’s performance. Monitor metrics such as accuracy and loss to detect any sudden or significant changes that may indicate potential membership inference attacks.
Tip 5: Utilize Encrypted Data
Encrypt sensitive data before using it for model training. Encryption adds an extra layer of protection, making it more difficult for attackers to access and exploit the data, even if they gain access to the model itself.
Summary: By implementing these tips, organizations can strengthen the security of their logistic regression models and minimize the risk of membership inference attacks. These measures safeguard the privacy of individuals whose data contributes to model development and ensure the integrity and reliability of machine learning applications.
Conclusion
Membership inference attacks pose significant privacy risks in the realm of machine learning. By exploiting the relationship between a model’s parameters and training data, attackers can determine whether an individual’s data was used to train a specific model. This can lead to the exposure of sensitive information and compromise the privacy of individuals.
Logistic regression models, widely used for binary classification tasks, are particularly susceptible to membership inference attacks. To mitigate these risks, researchers have developed various defense mechanisms, including differential privacy, synthetic data, and regularization techniques. By implementing these measures, organizations can enhance the security of their logistic regression models and safeguard the privacy of individuals whose data is utilized in model training.
As the field of machine learning continues to evolve, it is crucial to remain vigilant against emerging threats such as membership inference attacks. By adopting robust defense mechanisms and promoting responsible data handling practices, we can ensure the ethical and privacy-preserving use of machine learning models.





