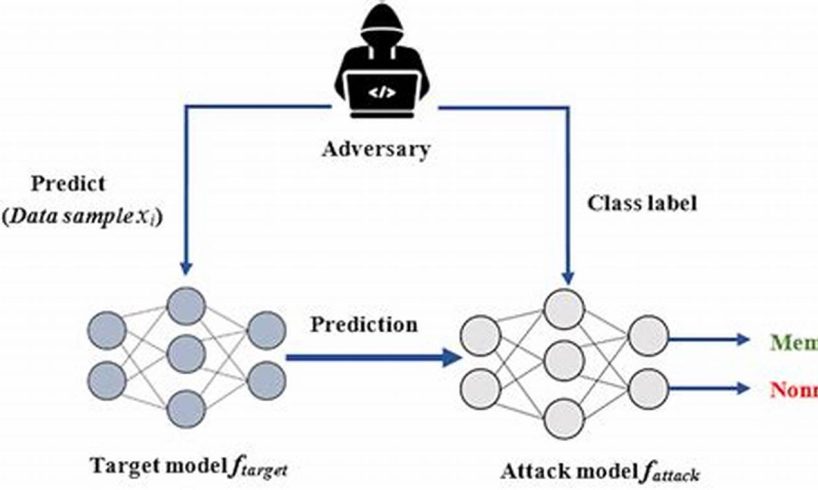

Membership inference attacks (MIAs) are a type of privacy attack in which an adversary attempts to infer whether a given data point was used to train a machine learning model. MIAs can be successful even when the adversary does not have access to the training data or the model parameters. One common target of MIAs is logistic regression models, which are widely used for binary classification tasks.
There are a number of different techniques that can be used to launch MIAs on logistic regression models. One common technique is to use a shadow model. A shadow model is a model that is trained on a dataset that is similar to the training data for the target model. The adversary then uses the shadow model to make predictions on the target model’s training data. If the shadow model’s predictions are accurate, then it is likely that the target model was trained on the same data.
MIAs can have a number of negative consequences. For example, MIAs can be used to identify individuals who have participated in sensitive research studies or who have provided their data to companies. MIAs can also be used to track individuals’ online activity or to target them with advertising.
1. Data Privacy

Membership inference attacks (MIAs) are a type of privacy attack in which an adversary attempts to infer whether a given data point was used to train a machine learning model. MIAs can be successful even when the adversary does not have access to the training data or the model parameters. One common target of MIAs is logistic regression models, which are widely used for binary classification tasks.
MIAs can compromise the privacy of individuals whose data was used to train a model. This is because if an adversary can successfully infer that a particular data point was used to train a model, they may be able to learn sensitive information about the individual. For example, if an adversary can infer that a particular individual’s medical data was used to train a model, they may be able to learn about the individual’s health conditions or treatments.
The privacy implications of MIAs are significant. MIAs can be used to identify individuals who have participated in sensitive research studies or who have provided their data to companies. MIAs can also be used to track individuals’ online activity or to target them with advertising.
It is important to understand the privacy risks of MIAs and to take steps to mitigate these risks. One way to mitigate the risk of MIAs is to use differential privacy techniques. Differential privacy is a set of techniques that can be used to train machine learning models in a way that protects the privacy of individuals whose data is used to train the model.
By understanding the privacy risks of MIAs and taking steps to mitigate these risks, we can help to protect the privacy of individuals whose data is used to train machine learning models.
2. Model Security
Membership inference attacks (MIAs) are a type of privacy attack in which an adversary attempts to infer whether a given data point was used to train a machine learning model. MIAs can be successful even when the adversary does not have access to the training data or the model parameters. One common target of MIAs is logistic regression models, which are widely used for binary classification tasks.
MIAs can be used to assess the security of machine learning models by identifying potential vulnerabilities. For example, if an adversary can successfully infer that a particular data point was used to train a model, they may be able to learn how to manipulate the model to make incorrect predictions. This could have serious consequences, such as allowing an adversary to evade detection by a fraud detection system or to manipulate a recommendation system to promote their own products.
By understanding how MIAs work and how to mitigate them, we can help to improve the security of machine learning models and protect them from attack.
Here are some specific examples of how MIAs can be used to assess the security of machine learning models:
- An adversary can use MIAs to identify which features are most important to a model. This information can then be used to craft adversarial examples that are designed to fool the model.
- An adversary can use MIAs to identify which data points are most likely to be misclassified by a model. This information can then be used to target those data points with attacks.
- An adversary can use MIAs to identify which parts of a model are most vulnerable to attack. This information can then be used to develop targeted attacks against those parts of the model.
By understanding how MIAs work, we can develop strategies to mitigate them and improve the security of machine learning models.
3. Adversarial Attacks

Membership inference attacks (MIAs) are a type of privacy attack in which an adversary attempts to infer whether a given data point was used to train a machine learning model. MIAs can be successful even when the adversary does not have access to the training data or the model parameters. One common target of MIAs is logistic regression models, which are widely used for binary classification tasks.
- Evasion Attacks: MIAs can be used to identify data points that are likely to be misclassified by a model. This information can then be used to craft adversarial examples that are designed to fool the model. For example, an adversary could use a MIA to identify which images in a dataset are likely to be misclassified as cats. The adversary could then use this information to create adversarial examples of cats that are designed to be misclassified as dogs.
- Poisoning Attacks: MIAs can be used to identify which data points are most important to a model. This information can then be used to craft poisoned data points that are designed to manipulate the model’s behavior. For example, an adversary could use a MIA to identify which features are most important to a fraud detection model. The adversary could then use this information to create poisoned data points that are designed to cause the model to make false positives.
- Model Extraction Attacks: MIAs can be used to extract information about the structure and parameters of a machine learning model. This information can then be used to develop more sophisticated adversarial attacks against the model. For example, an adversary could use a MIA to extract the weights of a logistic regression model. The adversary could then use this information to develop an adversarial attack that is designed to exploit the model’s weaknesses.
By understanding the connection between MIAs and adversarial attacks, we can develop strategies to mitigate both types of attacks and improve the security of machine learning models.
4. Differential Privacy

Differential privacy is a set of techniques that can be used to train machine learning models in a way that protects the privacy of individuals whose data is used to train the model. Differential privacy works by adding noise to the data that is used to train the model. This noise makes it difficult for an adversary to infer whether a particular data point was used to train the model.
- Facet 1: Evaluating the effectiveness of differential privacy
MIAs can be used to evaluate the effectiveness of differential privacy techniques in protecting against membership inference. By conducting a MIA on a model that has been trained using differential privacy, an adversary can determine whether the differential privacy techniques were effective in preventing membership inference. - Facet 2: Identifying weaknesses in differential privacy implementations
MIAs can be used to identify weaknesses in differential privacy implementations. By conducting a MIA on a model that has been trained using differential privacy, an adversary can identify ways to exploit the implementation to infer membership. - Facet 3: Developing new differential privacy techniques
MIAs can be used to develop new differential privacy techniques. By understanding how MIAs work, researchers can develop new differential privacy techniques that are more resistant to membership inference.
By understanding the connection between MIAs and differential privacy, we can develop strategies to improve the privacy of machine learning models and protect individuals’ data.
5. Model Inversion
Model inversion attacks and membership inference attacks (MIAs) are both types of privacy attacks that can be used to extract information from machine learning models. Model inversion attacks aim to recover the training data that was used to train a model, while MIAs aim to infer whether a particular data point was used to train a model.
- Facet 1: Shared techniques
Both model inversion attacks and MIAs can use similar techniques to extract information from machine learning models. For example, both types of attacks can use shadow models to infer information about the training data or the model parameters. - Facet 2: Different goals
Despite using similar techniques, model inversion attacks and MIAs have different goals. Model inversion attacks aim to recover the training data that was used to train a model, while MIAs aim to infer whether a particular data point was used to train a model. This difference in goals leads to different attack strategies and different implications for privacy. - Facet 3: Privacy implications
Both model inversion attacks and MIAs can have privacy implications. Model inversion attacks can be used to recover sensitive information about the individuals whose data was used to train a model. MIAs can be used to track individuals’ online activity or to target them with advertising. - Facet 4: Defenses
There are a number of defenses that can be used to mitigate the risk of model inversion attacks and MIAs. These defenses include using differential privacy techniques, using regularization techniques, and using data augmentation techniques.
By understanding the connection between model inversion attacks and MIAs, we can develop strategies to mitigate both types of attacks and improve the privacy of machine learning models.
6. Shadow Models
In the context of membership inference attacks (MIAs) on logistic regression models, shadow models play a crucial role. A shadow model is essentially a surrogate model that is trained on a dataset that is similar to the training data of the target logistic regression model. The goal of using a shadow model is to mimic the behavior of the target model as closely as possible. By making predictions on the target model’s training data using the shadow model, an attacker can infer whether a given data point was used to train the target model.
The effectiveness of a shadow model in launching a successful MIA depends on how well it can approximate the target model. If the shadow model is able to make accurate predictions on the target model’s training data, then it is more likely that the attacker will be able to correctly infer membership. This highlights the importance of using robust training procedures and regularization techniques to prevent overfitting in the shadow model.
The use of shadow models in MIAs raises significant privacy concerns. By successfully inferring membership, an attacker can potentially identify individuals whose data was used to train a particular machine learning model. This information could be used for a variety of malicious purposes, such as targeted advertising, identity theft, or discrimination. It is therefore crucial to develop effective defenses against MIAs, such as differential privacy techniques and model obfuscation.
7. Regularization
In the context of membership inference attacks (MIAs) on logistic regression models, regularization techniques play a critical role in enhancing model robustness and protecting against membership inference. Regularization involves modifying the loss function used during training to penalize overly complex models and encourage simpler, more generalizable models.
- Facet 1: Reducing Overfitting
Regularization techniques help reduce overfitting, a phenomenon where a model performs well on the training data but poorly on unseen data. By penalizing complex models, regularization encourages the model to learn more generalizable patterns, making it harder for an attacker to infer membership based on the model’s predictions.
- Facet 2: Improving Generalization
Regularization techniques promote better generalization, ensuring that the model performs well on data beyond the training set. This makes it more challenging for an attacker to craft adversarial examples that can successfully infer membership, as the model is less likely to make confident predictions on out-of-distribution data.
- Facet 3: Enhancing Robustness
Regularization enhances the overall robustness of logistic regression models, making them less susceptible to various types of attacks, including MIAs. By reducing overfitting and improving generalization, regularization helps the model make more reliable predictions, reducing the attacker’s ability to exploit model weaknesses.
In summary, regularization techniques offer a valuable defense mechanism against MIAs on logistic regression models. By promoting simpler, more generalizable models, regularization reduces overfitting, enhances robustness, and improves the overall security of machine learning models.
8. Dataset Bias
Dataset bias is a significant concern in machine learning, and it can have a substantial impact on the effectiveness of membership inference attacks (MIAs) on logistic regression models. A biased dataset is one that does not accurately represent the population from which it is drawn, and this bias can lead to the model making unfair or inaccurate predictions.
In the context of MIAs, dataset bias can make it easier for an attacker to infer whether a particular data point was used to train a logistic regression model. This is because the attacker can exploit the bias in the dataset to create adversarial examples that are more likely to be classified as members of the training set.
For example, consider a logistic regression model that is trained to predict whether a patient has a particular disease. If the training data is biased towards patients who have the disease, then the model is more likely to predict that a new patient has the disease, even if they do not. This bias can be exploited by an attacker to create adversarial examples of patients who do not have the disease, but who are classified as having the disease by the model. This could allow the attacker to infer that these patients were part of the training set.
The problem of dataset bias is a complex one, and there is no easy solution. However, there are a number of steps that can be taken to mitigate the impact of dataset bias on MIAs. One approach is to use differential privacy techniques, which can help to protect the privacy of individuals whose data is used to train a model. Another approach is to use regularization techniques, which can help to reduce the overfitting of a model to the training data.
By understanding the connection between dataset bias and MIAs, we can take steps to mitigate the impact of dataset bias and protect the privacy of individuals whose data is used to train machine learning models.
Frequently Asked Questions about Membership Inference Attacks on Logistic Regression Models
This section provides answers to common questions and addresses misconceptions regarding membership inference attacks (MIAs) on logistic regression models. Understanding these concepts is crucial for safeguarding the privacy of individuals and the integrity of machine learning models.
Question 1: What is a membership inference attack (MIA)?
An MIA is a type of privacy attack where an adversary attempts to determine whether a given data point was used to train a machine learning model. This can be achieved even without direct access to the training data or model parameters.
Question 2: Why are logistic regression models vulnerable to MIAs?
Logistic regression models are widely used for binary classification tasks and can exhibit vulnerabilities to MIAs due to their linear decision boundaries. Adversaries can exploit these boundaries to infer membership by observing the model’s predictions.
Question 3: What are the potential consequences of successful MIAs?
Successful MIAs can compromise the privacy of individuals whose data was used in model training. They can also reveal information about the model’s structure and training process, potentially aiding in adversarial attacks.
Question 4: How can we mitigate the risk of MIAs on logistic regression models?
Several techniques can be employed to mitigate MIA risks, including using differential privacy, regularization, and careful dataset selection to minimize bias. Additionally, implementing model hardening measures can further enhance model robustness against attacks.
Question 5: What are the ethical implications of MIAs?
MIAs raise ethical concerns as they can potentially lead to privacy breaches and discrimination. It is essential to consider the ethical implications when using machine learning models, particularly in sensitive domains involving personal data.
Question 6: What are the current research directions in MIA defense?
Ongoing research in MIA defense focuses on developing more robust and privacy-preserving machine learning algorithms. This includes exploring advanced differential privacy techniques, generative adversarial networks (GANs), and other novel approaches to protect model confidentiality while maintaining predictive performance.
In conclusion, understanding MIAs on logistic regression models is crucial for safeguarding privacy and data security in machine learning. By employing appropriate mitigation techniques and adhering to ethical considerations, we can harness the power of machine learning while ensuring the protection of individuals’ sensitive information.
Explore further: Advanced Techniques for Mitigating MIAs on Machine Learning Models
Tips to Mitigate Membership Inference Attacks on Logistic Regression Models
Membership inference attacks (MIAs) pose significant privacy and security risks to machine learning models. Here are some essential tips to mitigate these attacks and protect the integrity of logistic regression models:
Tip 1: Employ Differential Privacy
Differential privacy is a powerful technique that adds noise to training data, making it harder for adversaries to infer membership. By incorporating differential privacy into the training process, you can significantly reduce the risk of successful MIAs.
Tip 2: Implement Regularization Techniques
Regularization techniques, such as L1 and L2 regularization, penalize model complexity and promote generalization. Regularized models are less likely to overfit to the training data, making them more robust against MIAs.
Tip 3: Utilize Shadow Models for Defense
Shadow models are trained on a dataset similar to the training data of the target model. By analyzing the predictions of a shadow model on the target model’s training data, it is possible to detect potential membership inference vulnerabilities and take appropriate countermeasures.
Tip 4: Carefully Select and Preprocess Training Data
Dataset bias can exacerbate the effectiveness of MIAs. Carefully selecting and preprocessing the training data to minimize bias can make it harder for adversaries to exploit model vulnerabilities. Techniques like data augmentation and synthetic data generation can be employed to enhance data diversity and reduce bias.
Tip 5: Leverage Model Hardening Techniques
Model hardening involves applying various techniques to make models more robust against attacks. Adversarial training, where the model is exposed to adversarial examples during training, can help improve model resilience against membership inference attempts.
By following these tips, you can significantly mitigate the risk of MIAs on logistic regression models and protect the privacy and security of your machine learning applications. Remember, it’s crucial to continuously monitor and evaluate your models for potential vulnerabilities to ensure ongoing protection against evolving attack strategies.
Conclusion
Membership inference attacks (MIAs) pose a serious threat to the privacy and security of machine learning models, particularly logistic regression models. This article has explored the nature of MIAs, their implications, and various techniques to mitigate these attacks.
By employing differential privacy, implementing regularization techniques, leveraging shadow models, carefully selecting training data, and utilizing model hardening strategies, organizations and researchers can significantly reduce the risk of successful MIAs. These measures contribute to robust and secure machine learning models that protect the privacy of individuals and maintain the integrity of sensitive data.
As the field of machine learning continues to evolve, staying abreast of emerging attack techniques and developing innovative defense mechanisms will be critical. By fostering collaboration between researchers, practitioners, and policymakers, we can collectively address the challenges posed by MIAs and ensure the responsible and ethical use of machine learning technologies.





